


Redis的几种使用场景
- 缓存系统
- 计数器
- 社交
- 消息队列
- 排行榜
- 实时系统
Redis的几种启动方式
- 简单启动:
redis-server使用redis默认配置启动 - 动态参数启动:
redis-server options,使用动态参数,如:redis-server --port 6380 - 使用配置文件启动:
redis-server <config path>,如:redis-server /var/configs/6381.conf
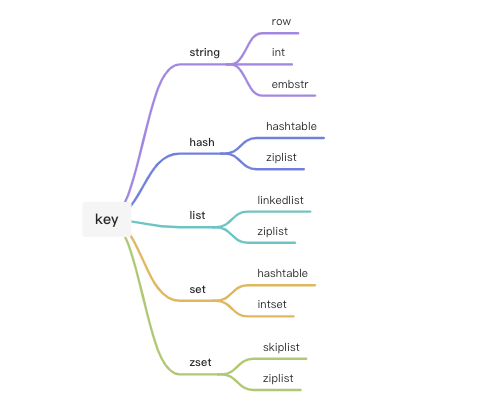
Redis的几种数据结构
- 字符串
string - 哈希
hash - 列表
list - 集合
set - 有序集合
zset
常用的通用命令
keys列出key,支持正则
生产环境中不宜滥用,该命令会执行全局扫描,因为redis是单线程的,容易造成阻塞影响性能。可以使用后面的
scan命令来代替,如果生产环境是集群的话,可以在从节点上执行keys这类重量级命令。
dbsize数据库中key的个数
这个命令不会执行全局扫描,使用的是Redis内置的全局计数器
exists判断数据库中是否含有指定keydel删除一个或多个keyexpire key <seconds>设置key的过期时间ttl查看key剩余的过期时间persist去掉key的过期时间type key查看key的数据类型
数据结构内部编码
因为Redis是单线程的,一次只能执行一个命令,如果指令执行时间过长,后续命令只能等待,所以线上生产环境要避免执行长命令,长命令有:
keysflushallflushdbslow lua scriptmutil/execoperate big value(collection)
数据详细结构
字符串 String
数据类型可以是字符串也可以是整形
场景
- 缓存
- 计数器
- 分布式锁
常用命令
get keyset key valuesetnx key value或set key value nxkey不存在时设置值set key value xxkey存在时设置值set key value ex seconds设置key值并设置过期时间(有没有该key都可以)del key删除key
整形操作:
mget key1 key2...批量获取一个或多个key的值mset key1 value1 key2 value2...批量设置一个或多个key-value对(原子操作)getset key new-value对key设置新值并返回旧值append key value将value追加到key值中strlen key获取字符串的字节长度(中文字符占两个字节)‘incrby key k自增k(整数),没有递减指令,但是可以通过传递负数实现递减incrbyfloat key k自增k(小数),没有递减指令,但是可以通过传递负数实现递减getrange start end获取字符串的范围,如果超出不会报错,返回空字符串setrange key index value从指定索引开始设置新值
哈希 Hash
存储方式为 key field value
常用命令
hash的命令都是以
h开头的
hget key fieldhgetall keyhset key field value如:hset user:1:info name johnhdel key field如:hdel user:1:info namehexists key field判断是否存在fieldhlen key获取字段个数hmset key field1 value1 field2 value2...批量设置多个属性(原子操作)hmget key field1 field2...批量获取key中的多个属性hkeys key获取key中的所有属性keyhvals key获取key中所有属性的valuehsetnx key field value当field不存在时,设置新值hincrby key field k字段值自增khincrbyfloat key field k字段自增k(小数)
列表 List
数据结构:
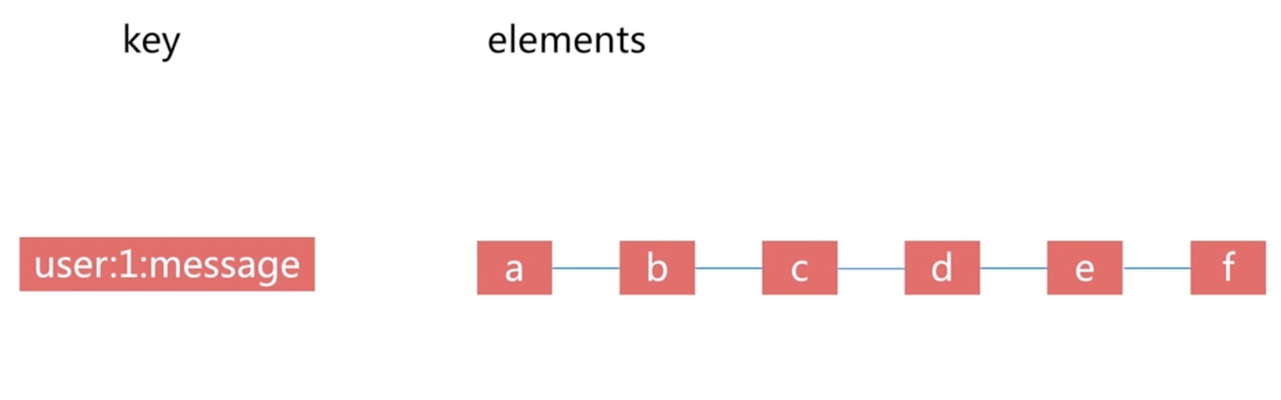
列表是一个有序可重复集合
常用命令
list的命令都是以 l 开头的
lpush key value1 value2...从左边一次插入多个值rpush key value1 value2...从右边一次插入多个值linsert key before|after item value在指定元素前|后插入valuelpop key从左边移除一个元素rpop key从右边移除一个元素lrem keys count item移除和item相同的元素,当count大于0时,从左到右删除;当count等于0时,删除所有;当count小于0时,从右到左删除。ltrim key start end对列表进行裁剪,保留索引为start到end之间的元素lrange key start end查询索引为start和end之间的元素(包含start和end,索引大于等于0为从左到右,如果小于等于-1,则是从右到左。所以如果查询所有所有元素可以简写为 lrange key 0 -1)lindex key index获取索引为index的元素llen key获取列表长度lset key index new-value将指定索引位置的元素替换为新值blpop key timeout以阻塞的方式从左端弹出元素,如果列表中有元素的话,立刻弹出;如果没有元素则等待;超市时间如果为0则表示一直等待。brpop key timeout同blpop,方向相反
集合 Set
无序不重复的元素集合,而且支持集合间操作
常用命令
命令都是以
s开头
集合内操作
sadd key value1 value2...向集合中添加一个或多个元素,如果集合中已存在要添加的元素,则添加不成功srem key item删除集合中的itemscard key获取集合中元素数量sismember key item判断元素是否存在于集合中srandmember key [count]随机获取集合中count个元素,默认为1spop key从集合中随机弹出一个元素(该元素将从集合中删除)smembers key获取集合中所有元素(无序的)
集合间操作
sinter key1 key2...计算集合间的交集sdiff key1 key2...计算集合间的差集sunion key1 key2...计算集合间的并集
集合间的操作命令加上 store 就是将操作结果存储到指定key中:
sinterstore dest-key key1 key2...计算集合间的交集并将结果存储到 dest-key 中sdiffstore dest-key key1 key2...同上sunion dest-key key1 key2...同上
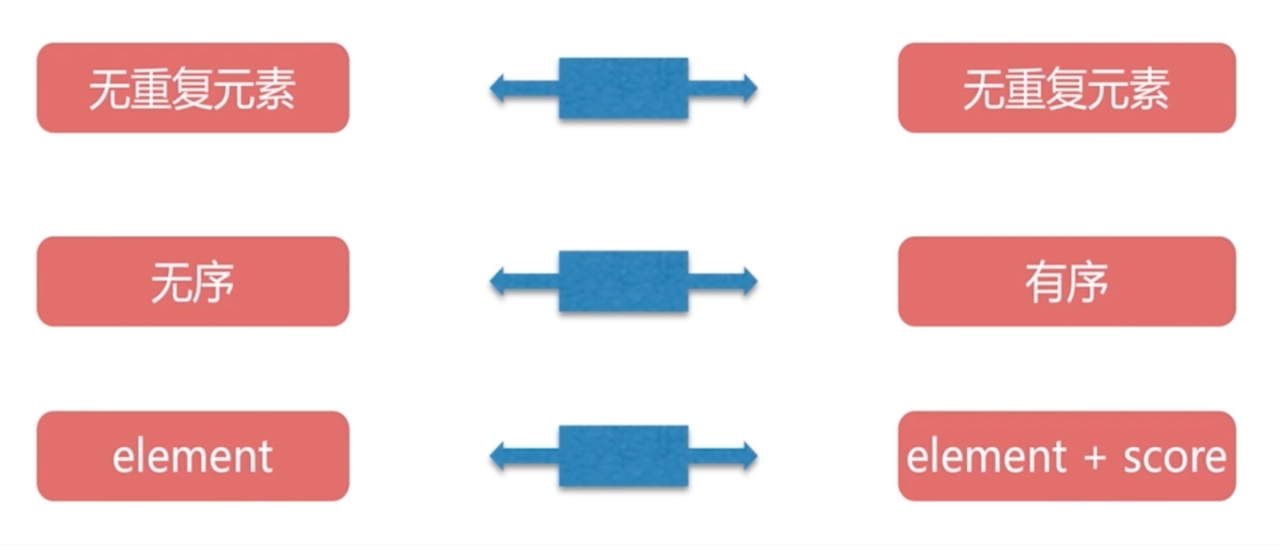
有序集合 ZSet
有序集合相对于无序集合的差异:
常用命令
ZSet的命令都是以
z开头
zadd key score1 item1 score2 item2...添加元素zrem key item1 item2...删除元素zscore key item获取元素的分数zincrby key k item元素的分数加k,如果元素不存在,则是0+kzcard key获取集合中的元素个数zrank key item获取item的排名(从小到大)zrange key start end [withscores]获取指定范围的元素zrevrange key start end [withscores]反向排序获取指定范围的元素zrangebyscore key min max [withscores]获取指定分数范围内的元素zrevrangebyscore key max min [withscores]反向获取指定分数范围内的元素zcount key min max获取指定分数范围内的元素个数zremrangebyscore key min max按照分值范围删除元素zremrangebyrank key start end按照排名范围删除元素
集合间的操作同样适用于zset,但是需要指定key的个数:
zinter num-key key1 key2...num-key 是指后面集合的个数zdiff num-key key1 key2...同上zunion num-key key1 key2...同上
zset的集合间操作同样也支持添加 store 修饰符用于持久化,zset 的集合间操作 不会比较分数,得到的结果的分值会被相加。
慢查询
生命周期
一个指令执行可分为4个阶段:发送指令 -> 排队 -> 执行命令 -> 返回结果
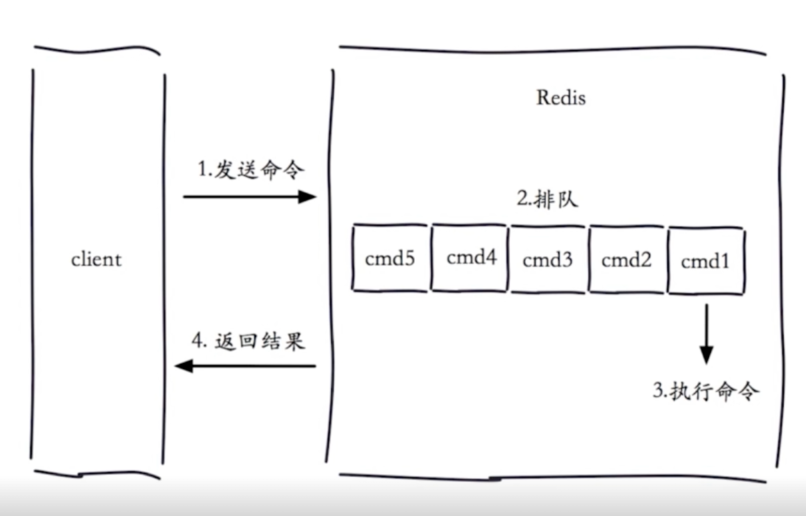
其中慢查询发生在 执行命令 阶段
客户端超时不一定是慢查询引起的,但是慢查询是客户端超时的一个kennel因素
pipeline
如果分批次执行n个命令,就会消耗n次网络时间;可以使用 pipeline 来通过一次网络请求,执行多个命令,进而减少网络时间的消耗。
pipeline 和带有 m 的批量操作命令是有本质区别的:
pipeline 是将多个命令打包一次发送到服务器,在服务端重新拆包等待执行,执行之后再打包返回客户端,所以 pipeline 不是原子操作。带有 m 端批量操作指令是原子性的
注意事项:
- 注意每次 pipeline 携带的数据量
- pipeline 每次只能作用在一个redis节点上
- m 操作与 pipeline的区别
发布订阅
redis只实现了简单的发布订阅功能,无法实现消息堆积,不能追溯以前的消息。
常用命令
publish channel message向对应频道发送消息,返回订阅者数subscribe channel1 channel2...订阅频道unsubscribe channel取消订阅频道psubscribe pattern按照匹配规则订阅频道,如果:psubscribe openbook:*pubsubscribe pattern按照匹配规则取消订阅频道pubsub channels <pattern>找出订阅者至少为1的频道pubsub numsub channel获取channel的订阅数量(不包含按照规则订阅的订阅者)pubsub numpat获取被订阅的规则总数 如:openbook:* channel:*
消息队列
借助 list 对阻塞,实现消息的抢购消费
位图 Bitmap
Bitmap在redis中不是一个新的数据类型,其借助的是字符串,如果使用type命令来查看其数据类型的话,发现是字符串类型。
使用场景
-
用户签到
很多网站都提供了签到功能,并且需要展示最近一个月的签到情况,这种场景可以使用bitmap来实现。根据日期offset = 一年中的第几日key = 年份:用户id -
统计活跃用户(用户登录情况)
使用日期作为key,然后用户id为offset,如果当日活跃过就设置为1
假如20221218的活跃情况是:[1,0,1,1,0,1],20221219的活跃用户情况是:[1,1,1,1,0,1],统计连续两天活跃的用户总数:
bitop and res 20221218 20221219
bitcount res
统计20221218~20221219活跃过的用户:
bitop or res 20221218 20221219
bitcount res
- 统计用户是否在线
如果需要提供一个查询当前用户是否在线的接口,也可以考虑使用bitmap。既节约空间又高效。只需要一个key,然后用户id为offset,如果在线就设置为1,不在线就设置为0.
常用命令
setbit key offset valuevalue值只能是0或者1getbit key offset获取偏移offset的值bitcount key [start end]获取指定范围内1多个数,如果不指定start和end,则计算全部bitop options destKey key1 key2...对多个key进行操作
and 与运算符 &
or 或运算符 |
xor 异或 ^
not 取反 ~
这些操作都是对每个bit位上的值进行操作
bitop key value返回key中第一个位value的索引
经纬坐标Geo
使用type命令发现,geo的类型是zset,基于zset实现,所以成员操作可以使用zset的相关命令
常用命令
geoadd key longitude latitude member添加经纬度geopos key member获取成员经纬度坐标geodist key member1 member2 [unit]计算两个成员之间的距离(unit:m、km、mi英里、ft英尺)georadius key longitude radius [unit] [partoptions]获取指定经纬度距离范围内的成员
partoptions 可以是以下情况:
withcoord:返回结果包含经纬度
withdist:返回结果包含距离中心点的距离
withhash:返回结果包含geohash
COUNT count:指定返回结果的数量
asc | desc:返回结果按照距离中心点的距离进行升序 | 降序排列
store key:将返回结果的地理位置信息保存到指定键,存储到了一个zset中,score是在geo中的hash值。
storedist key:将返回结果距离中心点的距离保存到指定键中,存储到一个zset中,score是到中心点的距离。
持久化
持久化的方式有 快照 和 日志
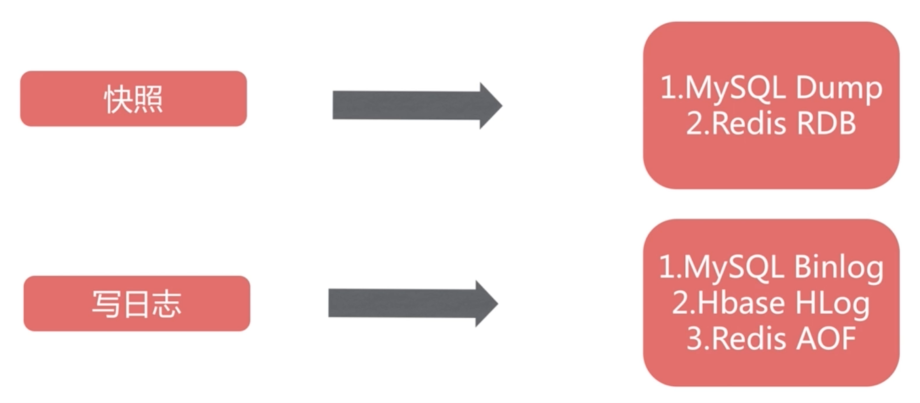
快照模式 RDB
触发RDB持久化的方式有三种:save(同步命令)、bgsave(异步命令)、自动(根据一定阈值条件自动触发)生成rdb文件,redis可以根据rdb文件恢复磁盘上持久化的数据。
save 命令会阻塞其他命令,bgsave 使用的是子线程执行快找操作,不会阻塞其他命令的执行,但是生成子线程的操作是会阻塞其他命令的执行的
redis配置文件中默认的rdb生成策略:
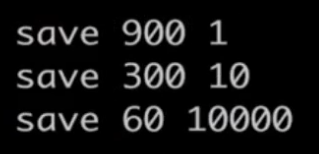
RDB 方式存在的问题 :
- 耗时、耗性能
- 不可控、容易丢失数据
日志模式 AOF
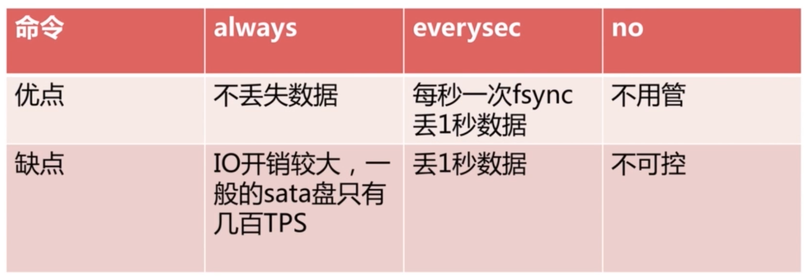
原理:写命令刷新到缓存区,然后根据一定策略将缓冲区中的命令写入磁盘持久化,AOF模式的三种策略:always、everysec、no:
- alwasy:每条命令都会写入磁盘
- eveysec:每秒将缓冲区中的命令写入磁盘中
- no:系统将自动决定什么时候将缓冲区中的命令写入磁盘中
三种策略对比
随着命令的增多,AOF日志文件会逐渐增大,redis为了解决这一点,会将AOF中的命令进行重写:将重复的、过期的、多次操作进行简化:

这样可以减小磁盘占用、增加恢复速度
AOF重写配置:
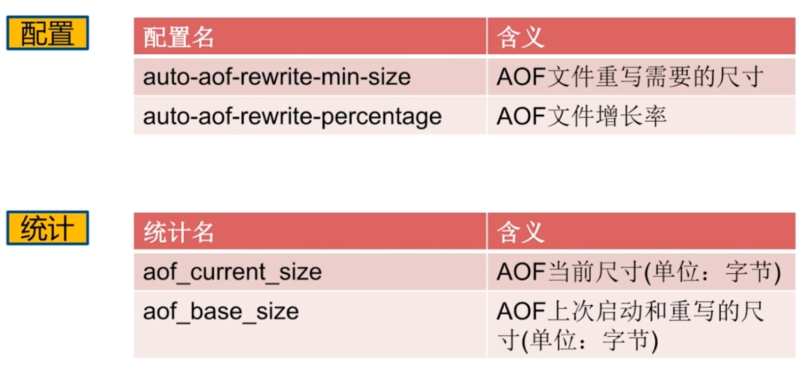
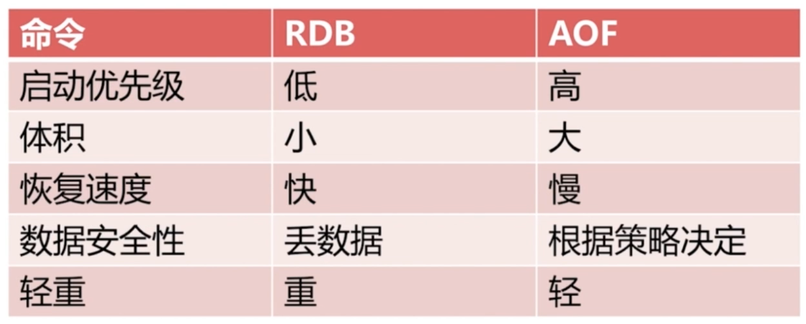
RDB和AOF对比取舍
主从复制
- 从节点为主节点提供了数据备份
- 对读写进行分流,减轻主节点压力
主从复制存在的问题
当主节点挂掉之后,只能手动转移
评论区